
SR-ReaL solves spatial reasoning through two complementary paths: Language-Only Reasoning (LOR) for step-by-step linguistic deduction, and Detect-Then-Reason (DTR) for explicit 3D grounding followed by geometric inference.
Spatial VLMs have made substantial progress in geometric perception, yet complex spatial reasoning, requiring multi-step inference over depth, distance, and scene relations, remains challenging. Moreover, different spatial queries call for fundamentally different strategies: some are best addressed through purely linguistic, step-by-step deduction, while others require explicit 3D grounding before quantitative inference. We present Dual-Path Spatial Reasoning via Reinforcement Learning for Spatial VLMs (SR-ReaL), a unified framework that equips a spatial VLM with two complementary reasoning paths: Language-Only Reasoning (LOR), which performs step-by-step linguistic deduction, and Detect-Then-Reason (DTR), which detects 3D geometric cues (e.g., centers or bounding boxes) via region tokens before explicit geometric inference.
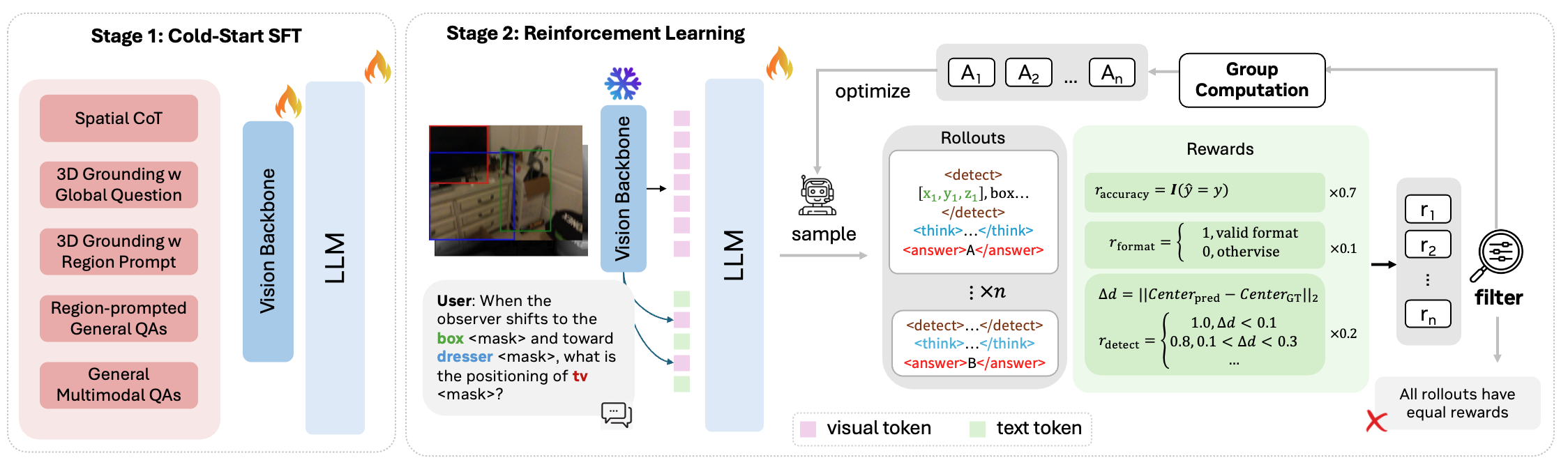
SR-ReaL starts with cold-start supervised fine-tuning that constructs LOR and DTR chain-of-thought supervision and exposes a region-to-3D interface. It then applies reinforcement learning with accuracy and format rewards; for DTR, a discrete center-based detection reward further improves geometric alignment. Across diverse spatial benchmarks, one RL-trained model supports both paths, achieves strong gains over spatial VLM baselines, and generalizes across datasets without per-task tuning.
SR-ReaL studies how reinforcement learning should shape spatial reasoning with the rich geometric perception provided by spatial VLMs.
A single spatial VLM supports both LOR for general spatial deduction and DTR for region-aware tasks that benefit from explicit 3D coordinates.
Region tokens bridge 2D references and 3D quantities, allowing DTR to predict object centers or boxes before computing distances and relations.
Cold-start supervision stabilizes reasoning traces, while RL with structured rewards improves both benchmark accuracy and cross-domain transfer.
Different spatial queries call for different strategies. SR-ReaL makes both available in the same checkpoint.
Best suited for global scene reasoning and questions that can be solved through relational deduction.
Observe visual and textual spatial relations.
Chain relations through concise step-by-step reasoning.
Select or generate the final answer without explicit detection.
Best suited for region-grounded and metric-sensitive questions involving depth, distance, or precise localization.
Use region tokens to ground referenced objects.
Predict 3D centers or boxes for the relevant regions.
Compute geometric relations and derive the answer explicitly.
SR-ReaL combines structured cold-start data with reinforcement learning rewards that supervise answer correctness, output format, and DTR localization.
Built on an SR-3D-style model with text, image, and region tokens plus 3D-aware visual embeddings.
Construct language-only and geometry-grounded reasoning traces, then filter for answer and rationale consistency.
Mix 2D/3D grounding, region-prompted spatial QA, and general multimodal data to preserve broad capability.
Optimize with accuracy and format rewards, plus a discrete detection reward for DTR 3D alignment.
One SR-ReaL checkpoint supports both inference paths and improves over the SR-3D spatial VLM baseline.
| Model | SPAR Low | SPAR Medium | SPAR High | SPAR Avg. | EmbSpatial | SAT |
|---|---|---|---|---|---|---|
| SR-3D (Base) | 24.1 | 37.6 | 40.1 | 33.4 | 72.5 | 63.0 |
| Ours-LOR | 58.5 | 47.7 | 67.3 | 60.5 | 79.2 | 68.7 |
| Ours-DTR | 61.1 | 46.9 | 68.3 | 61.9 | 81.3 | - |
Ours-DTR improves SPAR-Bench average accuracy from 33.4 to 61.9 over SR-3D.
Explicit region-to-3D grounding helps embodied positional reasoning.
LOR improves global spatial reasoning when no region prompts are available.



SR-ReaL offers a practical view of when explicit geometry helps and how RL should be initialized for spatial VLM reasoning.
When region references are available, detecting 3D cues before reasoning improves quantitative spatial tasks such as depth and distance.
Language-only reasoning strengthens global spatial QA and applies when explicit region prompts or 3D detections are unavailable.
LOR and DTR reinforce each other: linguistic reasoning regularizes DTR while geometry-aware training enriches spatial representations.
@article{ji2026srreal,
title = {Reinforcing Dual-Path Reasoning in Spatial Vision Language Models},
author = {Ji, Yatai and Cheng, An-Chieh and Fu, Yang and Chen, Yukang and Zhang, Han and Yang, Zhaojing and Huang, Wei and Cheung, Ka Chun and Han, Song and Murali, Vidya Nariyambut and Molchanov, Pavlo and Kautz, Jan and See, Simon and Yin, Hongxu and Luo, Ping and Liu, Sifei},
year = {2026}
eprint = {2606.17539},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}